logical 데이터 타입
데이터 분석을 수행하다보면 어떤 조건을 만족하는지 분석해야 할 경우가 왕왕 있다. 가령, 7월에서 9월 사이의 강우량이라던가, 시험 점수가 80점 이상인 학생들이 누구인지 분석한다던가, 여성이 아닌 남성들의 평균 키를 조사한다던가 하는 분석에서는 모두 “조건”을 만족하는 데이터들만 추출해야만 한다.
MATLAB에서 logical 데이터 타입은 이와 같은 “조건”을 충족하거나 충족하지 않는 데이터들을 구별해낼 때 아주 유용하게 사용할 수 있다. logical 데이터 타입은 참/거짓의 두 가지 상태만을 이용하며 여기에 논리 연산자들을 함께 사용한다.
logical 데이터 타입의 아이콘은 아래와 같다.
![]()
logical 데이터 타입은 Command Window에서 아래와 같이 입력해 정의해볼 수 있다.
>> a = true
a =
logical
1
>> b = false
b =
logical
0
Workspace를 보면 true로 정의한 a는 “1”, false로 정의한 b는 “0”으로 표기된 것을 알 수 있다. 실제로도 logical 타입 변수를 숫자처럼 더하면 그 때는 true는 1, false는 0으로 동작하도록 설계되어 있다.
만약, 벡터나 행렬로 구성된 true 혹은 false의 숫자열들을 구성하고 싶다면 함수 “true”나 “false” 뒤에 소괄호를 넣고 그 사이에 원하는 행, 열의 크기를 입력하자.
A = true(3, 3)
A =
3×3 logical array
1 1 1
1 1 1
1 1 1
벡터나 행렬로 구성된 logical 타입의 변수는 벡터나 행렬의 입력으로도 그대로 사용될 수 있다. 특정 index의 값이 true에 해당하면 그 원소의 값이 출력된다. 아래와 같은 예시를 살펴보자.
a = [1, 2, 3, 4, 5];
my_logical = [true, false, true, false, true];
a(my_logical)
ans =
1 3 5
논리 연산 함수
논리 연산 함수는 한 개 이상의 logical 타입 데이터를 입력으로 받아 논리 연산을 수행한다. numeric 타입 데이터를 다룰 때 덧셈(+), 뺄셈(-) 등이 기본 연산인 것 처럼 논리 연산에서는 and(&), or( | ), not(~) 과 같은 연산을 기본으로 한다.
&, and()
and(&) 연산자는 두 개의 logical 타입 데이터를 입력으로 받고 한 개의 logical 타입 데이터를 출력한다. and(&) 연산은 두 개의 logical 타입 데이터가 모두 참(true)일 때 참을 출력하고, 그렇지 않은 경우에는 모두 거짓(false)을 출력한다. 아래의 진리표에는 이 내용이 정리되어 있다.
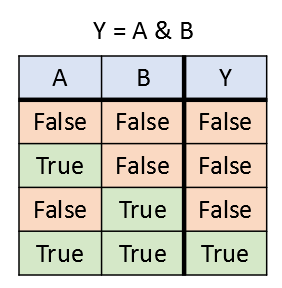
MATLAB에서는 앰퍼샌드 기호(&) 혹은 함수 “and”를 이용한다.
a = [false, false, true, true];
b = [false, true, false, true];
a & b
% and(a, b) % 위의 a & b와 동일함.
ans =
1×4 logical array
0 0 0 1
|, or()
or( | ) 연산자는 두 개의 logical 타입 데이터를 입력으로 받고 한 개의 logical 타입 데이터를 출력한다. or( | ) 연산은 두 개의 logical 타입 데이터 중 하나라도 참(true)이면 참을 출력하고, 두 개의 logical 타입 데이터 입력이 모두 거짓인 경우에만 거짓(false)을 출력한다. 아래의 진리표에는 이 내용이 정리되어 있다.
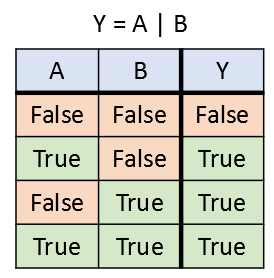
MATLAB에서는 수직선 기호( | ) 혹은 함수 “or”를 이용한다.
a = [false, false, true, true];
b = [false, true, false, true];
a | b
% or(a, b) % 위의 a | b와 동일함.
ans =
1×4 logical array
0 1 1 1
~, not()
not(~) 연산자는 한 개의 logical 타입 데이터를 입력으로 받고 한 개의 logical 타입 데이터를 출력한다. not(~) 연산은 입력이 true이면 false를 출력하고, 입력이 false 이면 true를 출력한다. 아래의 진리표에는 이 내용이 정리되어 있다.
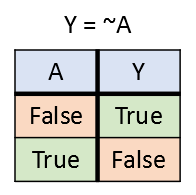
MATLAB에서는 틸드 기호(~) 혹은 함수 “not”을 이용한다.
a = [false, true]
~a
% not(a) % 위의 ~a와 동일함.
ans =
1×2 logical array
1 0
all
all 함수는 logical 데이터 타입 “벡터”를 입력으로 받고 한 개의 logical 타입 데이터를 출력한다. 이 함수는 입력 벡터의 모든 원소가 true일 때 true 값을 출력한다. 마치 and(&) 연산자와 비슷해 보이지만, 두 개의 입력을 받는게 아닌 하나의 벡터 입력을 받는다는데서 차이를 보인다.
a = [true, true, true];
b = [false, true, true];
all(a)
all(b)
ans =
logical
1
ans =
logical
0
any
any 함수는 logical 데이터 타입 “벡터”를 입력으로 받고 한 개의 logical 타입 데이터를 출력한다. 이 함수는 입력 벡터의 원소 중 하나라도 true일 때 true 값을 출력한다. 마치 or( I ) 연산자와 비슷해 보이지만, 두 개의 입력을 받는게 아닌 하나의 벡터 입력을 받는다는데서 차이를 보인다.
a = [false, false, true];
b = [false, false, false];
any(a)
any(b)
ans =
logical
1
ans =
logical
0
find
find는 입력 벡터/행렬의 원소 중 true 인 원소의 인덱스를 출력한다. 만약 입력이 행렬인 경우 출력에 행번호와 열번호를 각각 출력할 수 있다.
find([false, false, true, true])
[R, C] = find([true, true; false, true])
ans =
3 4
R =
1
1
2
C =
1
2
2
위 결과에서 R이 [1; 1; 2], C가 [1; 2; 2]가 나온 것은 입력 행렬의 (1행, 1열), (1행, 2열), (2행, 2열)에 true 값이 있다는 것이다.
관계 연산자
관계 연산자는 두 배열의 요소를 비교하고 논리값 true 또는 false를 반환하여 관계가 성립하는지를 나타낸다.
==, ~=
우선 “==” 연산자는 두 배열의 요소가 동일하면 참(true)을 출력하고 동일하지 않으면 거짓(false)을 출력한다.
a = (1 == 1)
b = (1 == 2)
a =
logical
1
b =
logical
0
여기서 절대 헷갈리면 안되는 것은 “=” 은 결과 값을 “a”라는 변수에 넣으라는 부호이고, “==”은 좌우의 값이 동일한지 판단하기 위한 “연산자”라는 점이다. 다시 한번 더 구체적으로 설명하면, 연산자는 “덧셈 기호” 같은 연산을 수행해주는 특수 기호이다.
반대로 “~=” 연산자는 두 배열의 요소가 동일하면 거짓을 출력하고 동일하지 않으면 참을 출력한다.
a = (1 ~= 1)
b = (1 ~= 2)
a =
logical
0
b =
logical
1
왜 “==” 하나만 있으면 될 것을 굳이 “~=” 같은 것도 만들었나 싶겠지만, 프로그래밍 논리를 구현해나가다 보면 “이거랑 저거랑 같으면~” 이라는 조건이 어울릴 때도 있지만 “이거랑 저거랑 다르면~” 이라는 조건이 어울릴 때도 있기 때문에 유저의 편의를 위해 두 개 다 만들어 둔 것이라고 보면 좋을 것 같다. 또, 참고로 매트랩에서는 다르다를 “!=” 와 같이 쓸 수는 없다.
>, >=, <, <=
이 연산자들은 왼쪽의 원소들이 오른쪽의 원소들에 비해 큰지, 크거나 같은지, 작은지, 작거나 같은지에 대해 판별해준다. 비교 대상은 스칼라 변수를 넣어도 되고, 벡터를 넣어도 괜찮다. 가령, 스칼라 끼리 비교하는 경우는 아래와 같이 단순하다.
1 > 2
ans =
logical
0
만약, 벡터를 이용해 여러 숫자들을 동시에 비교하고 싶다면 아래와 같이 수행할 수도 있을 것이다.
a = [1, 2, 3];
b = [1, 0, 4];
a > b
ans =
1×3 logical array
0 1 0
또는 좌변은 벡터, 우변은 스칼라인 경우도 가능하다.
a = [1, 2, 3];
a > 1
ans =
1×3 logical array
0 1 1
isequal
두 배열이 동일한지 판단해준다. “==” 연산자와 유사하다고 생각할 수도 있지만 “==” 연산자는 각각의 원소가 동일한지 하나씩 봐주는 연산을 수행하는 반면 “isequal”은 두 배열이 정말 같은지 안같은지에 관한 답을 내주는 차이가 있다.
A = magic(5);
B = A; B(1,1) = 1;
A == B
isequal(A, B)
ans =
5×5 logical array
0 1 1 1 1
1 1 1 1 1
1 1 1 1 1
1 1 1 1 1
1 1 1 1 1
ans =
logical
0
논리 연산을 이용한 데이터 분석
이제 위에서 배운 내용을 이용해 직접 데이터 분석을 수행해보도록 하자. 아래의 가상 데이터는 어떤 대학교 1학년 학생의 나이, 영어/수학 성적과 치킨/축구를 좋아하는지 여부에 대한 조사표이다.

이 데이터는 여기서 받을 수 있다.
데이터를 불러오기 위해 아래와 같이 “load” 함수를 사용하거나
load("logical_data_example.mat");
“logical_data_example.mat” 파일을 MATLAB Command Window에 드래그 & 드랍 하자.
둘 중 하나의 방법을 이용하면 Workspace에 아래와 같이 변수들이 입력되는 것을 알 수 있다.

변수들을 보면 어떤 변수는 numeric 타입 변수이고 어떤 변수는 logical 타입 변수인 것을 알 수 있다. 또, 각 변수의 원소 개수는 100개씩인 것을 알 수 있는데, 손으로 모든 변수를 일일히 파악하려면 꽤 시간이 걸릴 수 있고 더군다나 실수할 가능성도 있기 때문에 이런 데이터는 컴퓨터 프로그램을 이용해 분석하는 편이 더 낫다고 할 수 있다.
logical 데이터 타입과 관계 연산자 외에 추가로 사용될 함수들은 아래 페이지에서 소개한 함수들이라는 점을 미리 언급해둔다.
true 갯수 세기
배열이 true, false로 구성된 logical 타입 배열인 경우 true 갯수를 세기 위해서는 “sum” 함수를 사용할 수 있다. 처음에 언급했던 것 처럼 logical 타입 데이터를 더하면 true는 1로 동작하고 false는 0으로 동작한다. 따라서, “sum” 함수를 쓰면 true의 개수만큼 값이 출력될 것이다.
우선, 데이터에서 남자가 총 몇 명인지 파악해보자. 남자는 “is_male” 이라는 변수에 저장되어 있는데, 남자면 true, 여자면 false 값을 갖도록 지정되어 있다. 이를 위해 아래와 같이 입력해보자.
sum(is_male)
ans =
49
결과는 총 49명임을 알 수 있다. 같은 방법으로 치킨을 좋아하는 사람의 수와 축구를 좋아하는 사람의 수도 세어보자. 각각 69명과 31명임을 알 수 있을 것이다.
하나의 조건을 만족하는 데이터 찾기
이번에는 find 함수를 적극 활용해 특정 조건을 만족하는 데이터를 찾아보자. find 함수의 설명은 “0이 아닌 원소의 인덱스를 반환한다” 이다. 가령, 아래와 같이 축구를 좋아하는 학생들의 번호를 찾는데 쓸 수 있다.
find(is_footbal_lover)
ans =
Columns 1 through 14
7 9 11 13 22 24 29 31 33 39 40 41 42 47
Columns 15 through 28
48 49 50 51 56 59 61 65 69 71 72 76 86 90
Columns 29 through 31
91 92 93
이 결과를 보면 7, 9, …, 93번 학생들 총 31명이 축구를 좋아한다는 것을 알 수 있다.
이번에는 관계 연산자를 이용해 특정 조건을 만족하는 데이터를 찾아보자. 만약, 영어 점수가 70점 이상인 학생들을 찾고 싶다면 어떻게 해야할까? 아래와 같이 커맨드를 입력해보자.
english70up = score_english >= 70
이와 같이 입력하면 100개의 logical 타입 원소를 갖는 “english70up”이라는 벡터가 출력되는 것을 알 수 있다. 100개를 모두 체크하기는 어렵기 때문에 find 함수를 이어 사용해보도록 하자.
english70up = score_english >= 70;
find(english70up)
ans =
8 17 29 39 41 49 78 79 98
결과는 8, 17, … 98번 학생들이 영어 점수가 70점 이상이라는 것을 보여준다. 이처럼 find 함수는 “0”이 아닌 원소의 인덱스를 찾아주며 관계 연산자와 함께 사용하는 경우가 많다.
여러가지 조건을 동시에 만족하는 데이터 찾기
이번에는 논리 연산 함수들을 이용해 여러가지 조건을 동시에 만족하는 데이터를 찾아보자. 남학생들 중 축구를 좋아하는 학생들을 찾아보자. “sum” 함수와 “find” 함수를 쓰면 두 조건을 동시에 만족하는 학생이 몇 명이고 누구인지를 파악할 수 있을 것이다.
male_football_lover = is_male & is_football_lover;
sum(male_football_lover)
find(male_football_lover)
ans =
13
ans =
22 24 33 40 41 42 47 59 69 71 86 90 92
총 13명의 학생을 찾을 수 있고, 이 사람들은 22, 24, … 92번 학생이라는 걸 알 수 있다.
그러면, 남학생 중 영어 성적이 70점 이상인 사람들을 찾아보려면 어떻게 해야할까? 관계 연산자도 함께 사용하면 될 것이다.
male_englishup70 = is_male & (score_english > 70);
sum(male_englishup70)
find(male_englishup70)
ans =
3
ans =
41 79 98
반대로, 여학생 중 영어 성적이 70점 이상인 사람들을 찾으려면 어떻게 해야할까? not 연산자(~)를 활용해보면 될 것이다.
female_englishup70 = ~is_male & (score_english > 70);
sum(female_englishup70)
find(female_englishup70)
ans =
5
ans =
8 17 29 39 78
이번엔 영어 성적은 70점이 넘고, 수학 성적은 50점이 안되는 학생이 있는지 찾아보자.
englishup70_mathdown50 = (score_english > 70) & (score_math < 50);
sum(englishup70_mathdown50)
find(englishup70_mathdown50)
ans =
0
ans =
1×0 empty double row vector
결과를 보면 그런 학생은 없었다는 것을 알 수 있다. “영어를 잘 하는 학생이 수학도 잘 하는 것은 아니었을까” 하고 추정해볼 수 있다.
마지막으로 치킨을 좋아하거나 축구를 좋아하는 여학생이면서 수학 점수가 80점 이상인 학생을 알아보려면 어떻게 해야할까?
chicken_football_lover_female_mathup80 = (is_chicken_lover | is_football_lover) & ~is_male & score_math > 80;
sum(chicken_football_lover_female_mathup80)
find(chicken_football_lover_female_mathup80)
ans =
15
ans =
Columns 1 through 14
9 17 27 29 32 39 45 51 53 56 61 72 73 95
Column 15
96
이런 조건을 만족하는 학생들이 15명이 있다는 사실을 알 수 있다.
조건을 만족하는 데이터 교체하기
이번에는 특정 조건을 만족하는 데이터를 교체하는 실습을 수행해보자. 만약, 수학 점수가 90점 이상인 학생들은 모두 100점으로 처리하고 싶다고 해보자. 이럴 때 우선 수행해보아야 하는 것은 수학 점수가 90점 이상인 학생들이 누구인지 찾는 것이다.
mathup90 = score_math >= 90;
find(mathup90)
ans =
8 9 17 29 32 39 61 77
8, 9, …, 77번 학생 8명이 90점 이상의 수학 점수를 받았다는 것을 알 수 있다. 그렇다면, 이 학생들의 수학 점수를 100점으로 바꿔주기 위해선 어떻게 해야할까? 우리는 score_math의 8, 9, …, 77번째 값을 100으로 바꿔주기 위해 아래와 같이 입력할 수 있을 것이다.
score_math([8, 9, 17, 29, 32, 39, 61, 77]) = 100;
그러나, 도입부에서 “벡터나 행렬로 구성된 logical 타입의 변수는 벡터나 행렬의 입력으로도 그대로 사용될 수 있다.”고 언급한 사실을 기억하는가? 다시 말해 이런 방식으로 관계 연산자와 logical 타입 변수의 특성을 전부 활용해보자.
score_math(mathup90) = 100;
혹은 “mathup90” 과 같은 새로운 변수를 만들지 않더라도 한번에 이런 수행도 가능하다.
score_math(score_math >= 90) = 100;
score_math >= 90은 관계 연산자를 이용하여 작성된 것이며 결과가 logical 타입 변수를 담고 있는 벡터라는 점을 생각하면 왜 이런 한줄짜리 표현이 가능한지 이해할 수 있을 것이다.